


















Pocket Prep is a 10 year old SaaS company providing niche test prep for professional exams and certifications. We hire subject matter experts to create test questions, answers, explanations, and references for over 130 exams, and then we serve those up to users via our web and mobile clients. As a company, we are bootstrapped and comfortably profitable. Our team is currently 27 people, and we expect to hire a few more next year, but we have no plans for extreme growth or to take outside capital.
Technically, we are currently hosted on Heroku and handle roughly 30k DAU & 200k MAU. Our databases are hosted by MongoDB. Our Heroku and MongoDB instances are hosted on AWS us-east-1, so we have very low latency between our app servers and our data which is awesome. It does make us vulnerable to outages, though, and that will be something we address in the coming year.
Why we’re leaving
Since Heroku appears to be in ‘maintenance mode’ and the majority of their institutional knowledge has left… we will be leaving as well. We have roughly 24 different server instances on Heroku that cover five front-end sites and two servers. Each has develop, staging, and production instances, with several other test instances thrown in for automated testing.
Our boxes all utilize the vanilla Node build pack. Most of our dev/staging boxes use the hobby or 1x professional dyno. Our only ‘hefty’ box is our main app server that utilizes the performance L box and runs 35 instances of our server code using Node clustering. We found this to be more economical than horizontal scaling.
Who’s being considered
Based on our experience with Heroku and our lack of internal dev ops expertise, we have crossed off any services that would require hands-on maintenance. As a result, we have only looked at other PaaS offerings as our replacement. Our initial list included Digital Ocean App Platform, Engine Yard, Fly.io, Platform.sh, and Render.
We have a list of requirements, but the most pressing are:
– no maintenance
– Instant rollback
– 0 downtime deploy
– latency to our dbs
– redundancy
– jobs
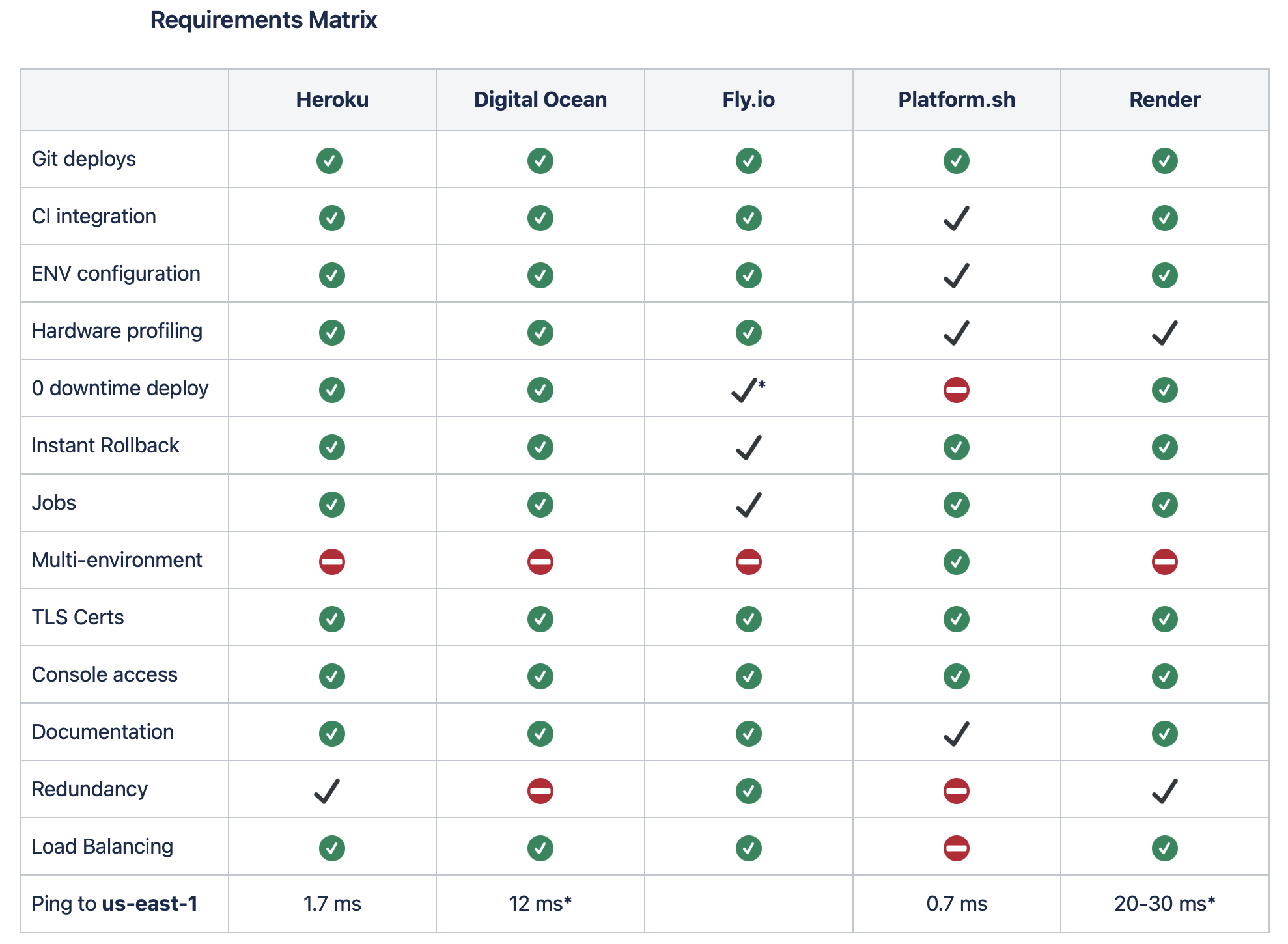
We crossed off Engine Yard quickly as it required Docker knowledge and manual certificate maintenance. Digital Ocean Droplets also fell into this ‘quick no’ column due to the Docker and image maintenance. Neither is particularly difficult, but we don’t spend time on them now and don’t need more to do. That doesn’t completely cross off Digital Ocean, though, as they still have their App Platform offering.
High hopes
It isn’t just about the technical stats either. The experience is pretty important. Heroku’s UX isn’t premium, but it gets the job done. One very interesting option for us to review was Platform.sh. They recognize the importance of multiple environments and bake that into the system from the start.
This was really compelling and a breath of fresh air. We would love to have six projects in our account instead of 24. The platform also rides on AWS, and we had the chance to select us-east-1, which resulted in similar low latency to our db as Heroku.
We really wanted to like Platform.sh and we think they are headed down a great path. Unfortunately, it also seems like they are in the midst of scaling, and it is a messy process right now. Getting connected with technical people was both easy and hard, similarly with the sales team.
Additionally, the platform is so tied to multi-environments and git that it feels very restrictive. Every platform makes assumptions and that is fine if they are well documented, but it took way too long to find someone that understood how the resources were allocated between the various environments and why we weren’t seeing what we expected.
We also found the resources available to the ‘sign up online’ plans to be limited, and setting up an enterprise account meant phone tag with people that didn’t seem to have the necessary info or tools to make things happen. The final deal breaker was finding out that the deploys were not 0 downtime. Setting ENVs one at a time wasn’t fun either…
Fly was pretty easy to set up and has a great dashboard and CLI. We haven’t been able to fully establish the latency yet to our db, but it is hosted fairly closely to us-east-1, and test calls to our endpoints were reasonable, albeit slower than DO or Render. We struggled quite a lot with some strange ENV behavior. After a lot of testing and back and forth with the team at Fly, we determined that the CLI was pulling in an `.env` file that we only used locally and not in our repo. However, it was in the directory, and thus the CLI was ingesting it.
There was one remaining ENV issue that burned a lot of our time; a fixed value for WORKERS that can’t seem to be overridden. We can definitely change what ENV we use, but having an ENV fixed that you can’t see is pretty unfriendly. We can set that variable and it shows the value we set, but that is NOT the value that is used when our app was run.
This ‘hidden’ value also made our initial setup very fraught as we were blowing RAM limits because it was starting 28 instances of our app instead of the 1 or 2 we were specifying. In the end, this was determined to be a bug in the Heroku build pack. Lastly, we also found the largest box there to be a little underpowered comparatively to Heroku, Render and DO, but those tests weren’t very exhaustive.
What’s left?
That leaves us with DO’s App Platform and Render. DO App Platform seems great and has the power of a public company behind it. It feels a little like IBM of yesterday, ‘no one ever got fired for choosing IBM.’
The UX is quite straightforward and comprehensive; it is comfortable and reminiscent of Heroku. We only had to make a small tweak to our build process to ensure it would compile on the box (raised the RAM limit for build due to our TypeScript compiler). Everything else was quite smooth and this seems like a viable option for us.
Our biggest concerns to date are the lack of redundancy options beyond same region horizontal scaling, and an observed higher variance in call times. Their engineers confirm the latter as a systemic issue with internal congestion. They recommend using Droplets for production and App Platform for the other environments as a solution.
Render was definitely the standout during testing. It just worked, period. From looking at their page to running on their platform, it was 30 min tops. No changes or tweaks, no ENV oddities and no resource issues. I put in our CC and could ratchet up and down our box size with ease. The fact that they have fixed IPs, zero downtime deploys, and DDOS via Cloudflare is clutch. This feels like a natural replacement for Heroku.
Interestingly they also ride on AWS, though us-east-2, not 1. Turns out that is fine for us as we can easily migrate our MongoDB instances to us-east-2 and end up with a similarly microscopic latency between app and db.
Our biggest concerns with Render are in redundancy, support, and company health. The largest of those, redundancy, isn’t really a concern as it is something we don’t have now, and they do offer. The issue is in the visibility of it. Fly.io makes it easy to set up fallback servers in other regions and load balance between them.
Render does add multi-region redundancy, but it is hidden from view and unable to be configured. This isn’t the worst thing as it exists, but ‘automagical’ isn’t a great default, in our opinion. Hopefully, they will expand on that functionalities’ configurability and visibility.
What’s next?
In the near term, we plan to roll out production servers on both DO App Platform and Render. We will point some of our lower use applications at those instances and monitor performance and uptime over a few months. Who knows, maybe we will learn something new or find another metric we haven’t considered that we should. Regardless, with several months of runtime, we expect to be in a much better place to feel confident in a new provider.
Stay tuned to hear how it goes and what we decide!